36 ways AI works alongside a freelance web developer
Last updated: May 7, 2026
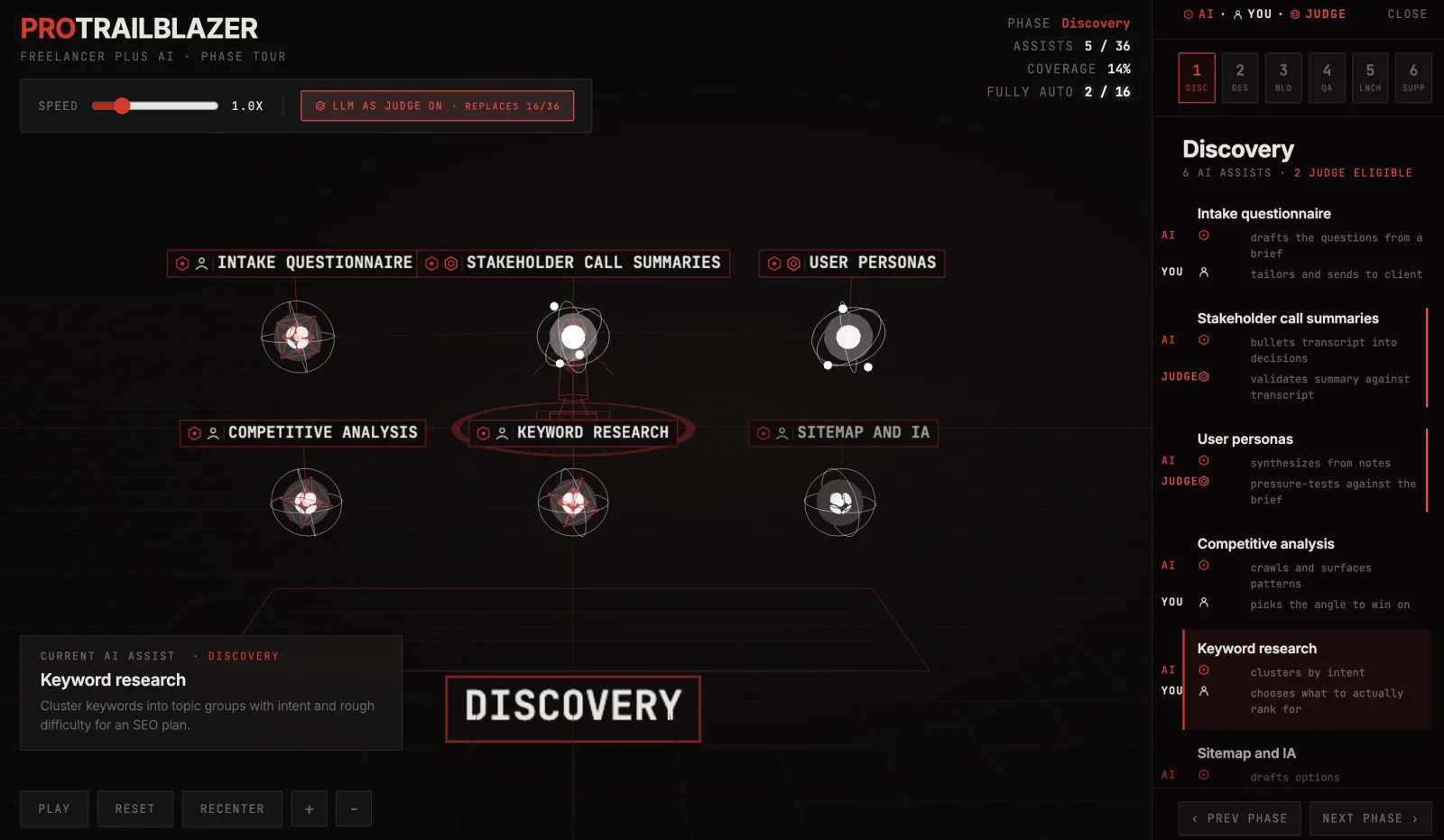
The interactive below tours one freelance web project end to end, six phases of six AI assists each: discovery, design, build, QA, launch, support. Press play to ride through the whole thing, click any node or row to inspect a single handoff, or flip the LLM as judge toggle to see which 16 of the 36 hand-offs can drop the human approver and run on their own.
Demo
Freelancer plus AI: a phase tour of 36 web project handoffs
An interactive 3D tour of six freelance web project phases (discovery, design, build, QA, launch, support) with six AI assists each, plus an LLM-as-judge toggle that reveals which 16 of 36 handoffs can drop the human approver.
What you're seeing
The figure at the center is the freelancer. Six clusters of nodes orbit around them, one per phase of a typical web project. Each cluster holds six AI assists, each one a real handoff a freelancer does on most jobs (intake questionnaire, sitemap drafts, layout variants, regex authoring, release notes, SEO meta review). The thin red beam from the freelancer's head to the active node is the current ask. Faint trails are previous asks in the same tour, so the constellation builds up as you go.
The right panel shows only the current phase's six assists, split into two roles per row: what the AI drafts (red hex) and what you still own (warm-white person silhouette). The top-right HUD tracks Phase, Assists lit out of 36, Coverage percent, and Fully auto, the count of handoffs that have flipped to a fully-AI loop.
A few things to try in the demo:
- Press Play. The camera pans to Discovery, ignites all six Discovery assists in sequence, then pans to Design and repeats through Support. The bottom-left card always names the current handoff and what it does.
- Toggle LLM as judge. The 16 eligible nodes morph from red wireframe octahedrons into glowing white atoms with three orbiting electrons. The Fully auto count in the HUD lights up to track how many of those have lit up in the current tour.
- Click any row or node. The camera jumps to that phase if needed, the panel scrolls to the row, and the bottom-left card shows the full description of what AI does and what you still do.
- Use the phase tabs. Tabs 1 through 6 jump between Discovery, Design, Build, QA, Launch, and Support. Press Play again to resume from where you left off.
- Pull the speed slider. 0.5x lets you read every assist as it ignites. 3x is the high-altitude flyover.
How it actually works
Each of the 36 nodes is a real freelancer handoff with three fields: what the AI does, what you do, and (for 16 of them) what an LLM judge does instead. The assists are not invented for the demo. "Bullets transcript into decisions", "spits out three to four layout options", "writes rules and messages", "audits and proposes rewrites". These are the reasoning steps a freelancer actually outsources to a model on real jobs, the same shape as a that produces an artifact instead of an answer.
When LLM as judge is off, every row has two roles: AI drafts, you validate. That is the pattern that runs almost every freelancer-with-AI workflow today. You hold the approve button. The 16 nodes marked judge-eligible have a single property in common: their human role is rubric-shaped. Compare against a transcript. Score brand fit against guidelines. Verify behavior preservation. Surface missing test cases. These tasks are not creative, they are evaluative, and they have a clear right answer or a clear scoring criterion.
Flip the toggle and those rows swap to a JUDGE role. The pattern, , is exactly what it sounds like: a separate model call (often the same family) graded against the rubric instead of the human. In the demo this is visualized as the white atom with three electrons orbiting, deliberately distinct from the red octahedron. When the judge agrees, the handoff is fully autonomous. When it does not, the work goes back to the AI for a retry, and only escalates to you on repeated failure. For a deeper look at the bias modes a judge can hide, see our full LLM-as-judge breakdown.
Three details map to how this looks in real systems:
- Drafting and judging are the same model class. The judge is not magically smarter, it is the same kind of LLM call with a different prompt and a clear criterion. The architecture that wires drafter, judge, and retry loop together is an , not a single super-model.
- Each judge call is a scoped agent. It has one job ("score this draft against this rubric"), no other tools, and a fixed output shape. That makes it a textbook in the strict sense, narrow and disposable, not the chat-anything kind.
- Some assists call out to real systems. Bug reproduction needs a code runner. SEO meta review needs a crawl. Test fixture data needs a database connection. Those steps are inside the assist, not just text generation, and the judge has to be allowed to read the same tool output to score against ground truth.
On the layout-variant assist ("spit out three to four options so you pick rather than start blank"), the judge step is roughly a pattern: generate four candidates, have the judge score each on the rubric ("matches brand, balanced grid, clear hierarchy, accessible contrast"), and surface the top one. The freelancer never sees the losers. That is a meaningful change in where attention gets spent.
Where this breaks for a real freelancer
The constellation is clean. Live workflows have four kinds of mess that don't show up in a node-and-beam diagram.
First, the rubric is the product. A judge with a vague rubric ("is this on brand?") will hallucinate a confident yes on bad work, then a confident no on good work, and the variance hides inside the average. The 16 judge-eligible assists are eligible because their rubric can actually be written down. If your brand voice can't fit in five lines of criteria, the judge cannot evaluate it, and that step belongs back with you.
Second, accountability does not delegate. "Tailors and sends to client" is not judge-eligible. Not because the AI cannot draft the email, but because the freelancer is the one whose name is on the relationship. A judge can score the draft against a rubric all day. It cannot take responsibility for the send.
Third, the long tail is where judging fails. On the most common case ("a standard validation form for a standard signup"), the judge will be right almost every time. On the weird case ("the client wants the date picker to default to last Wednesday because of a regulatory thing"), the judge has no rubric for that and will silently approve a wrong implementation. A judge-replaceable workflow is only safe with an escalation rule when confidence is low or the input is out of distribution.
Fourth, the work that survives is hard to explain. After the judge takes over the rubric-shaped 16, what is left for the freelancer is exactly the relational, the accountable, the contextual, and the genuinely novel. That is harder to scope on a quote and harder to bill hourly. The economics shift faster than the contracts do.
Key takeaways
- AI assist is no longer a yes-or-no question on a freelance web project. It shows up in every phase, from intake to support, and the meaningful axis is which steps still need a human approver, not which steps the AI can touch at all.
- Of 36 typical handoffs, 16 are rubric-shaped enough for an LLM judge to take over. The remaining 20 stay human because they are relational, accountable, or context-bound, not because the model cannot draft them.
- The boundary between human-in-the-loop and fully autonomous tracks the shape of the validation work, not the difficulty of the creative work. A drafting step can be cheap and a checking step can be expensive, but only the rubric-shaped checking step is safely judge-replaceable.
- An LLM judge is not a smarter LLM. It is the same model class with a clear criterion and a narrow prompt. It works exactly as well as the rubric you can write.
- A solo freelancer who routes the 16 judge-replaceable steps to an automated reviewer does not just go faster, they raise the floor. The bar moves from "whatever I had attention for this week" to "whatever the rubric says", which is usually higher than a tired Friday afternoon human.