LLM as judge: one model grading another
Last updated: April 23, 2026
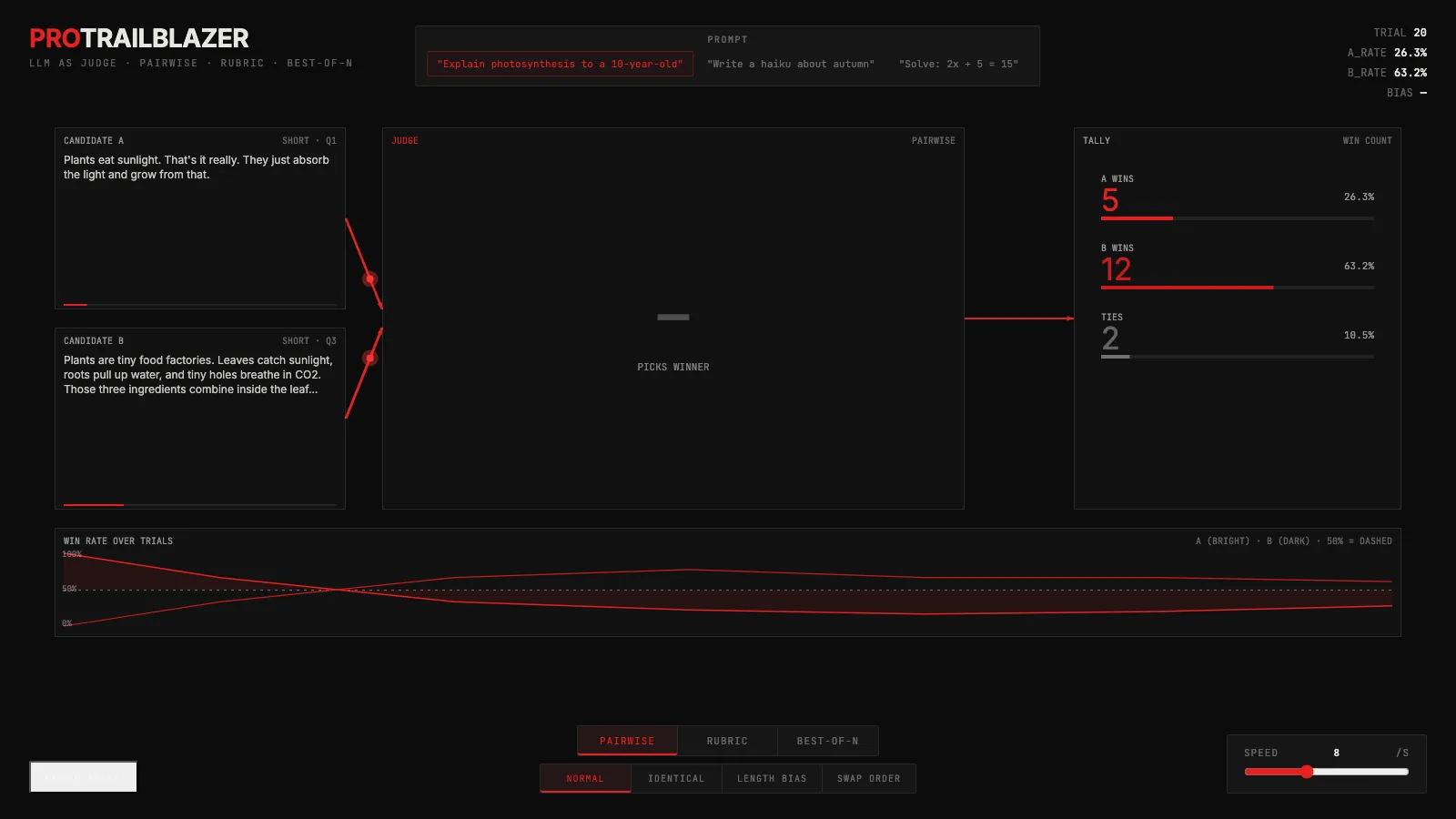
The interactive below puts one LLM in the judge slot and feeds it candidate answers from another. Switch between judging modes, run a bias probe, and watch the win rates drift as the judge's blind spots show up.
Demo
LLM as judge: pairwise, rubric, and best-of-N, with live bias probes
An interactive flow diagram where one LLM grades the output of another. Toggle the judge mode, run bias probes, and watch the win-rate and bias stats move in real time.
What you're seeing
Two candidate answers enter on the left. A single judge node in the middle reads them. A verdict exits on the right. The stat readout in the top-right tracks how often each candidate is picked across repeated trials, and BIAS reports how far that ratio has drifted from a fair 50-50 split.
The controls on top switch the judge's job:
- Pairwise. Given two answers A and B, pick the better one.
- Rubric. Give each answer an independent score on a short list of criteria, then sum.
- Best-of-N. Generate N candidates and have the judge pick the single best.
The bias probes at the bottom are diagnostic tools, not judging modes. They feed the judge comparisons where you already know the right answer, so any deviation from fair is measurable:
- Normal. Different answers, no rigging.
- Identical. A and B are the same text. Any deviation from 50-50 is pure position bias.
- Length bias. A and B are equivalent in meaning, but one is padded. Measures how much the judge rewards verbosity.
- Swap order. Runs the same comparison twice with A and B flipped. A fair judge returns the same verdict both ways.
How it actually works
Under the hood a pairwise judge is just a prompt template. Something like: 'Here is question Q. Here is answer A. Here is answer B. Which one is better? Respond with just A or B.' The judge generates , the first one is parsed, and that is the verdict. prompting asks the judge to reason first and state the letter afterward, which usually improves accuracy at the cost of latency and token count.
Rubric scoring uses a longer template: 'Rate this answer from one to five on correctness, from one to five on clarity, from one to five on completeness. Return JSON.' The judge emits a score per criterion, then the scores are summed or averaged. Because each candidate is scored in isolation, rubric judges are less sensitive to order effects than pairwise and more sensitive to the absolute wording of the criteria.
runs the generator N times and then runs the judge (in either mode) across the N outputs, keeping the top-ranked one. It is how you buy quality cheaply without retraining: throw compute at the problem and let the judge filter. See our walkthrough on inference-time compute for the scaling curves.
shows up in two places. The generator's temperature controls how different the N candidates are from each other (too low and you get near-duplicates, defeating the point of best-of-N). The judge's temperature is usually zero to keep verdicts deterministic across repeated runs.
The biases you have to probe for
Every LLM judge has systematic blind spots. Three common ones the demo lets you measure directly:
- Position bias. Show the same answer twice and a biased judge will still pick one slot more often. This is the most reliably documented LLM judge bias. Mitigation: run every comparison in both orders and average the result.
- Length bias. Judges tend to reward longer answers even when length adds no information. Mitigation: control for length explicitly in the prompt, or include a short-answer preference example in the instructions.
- Self-preference bias. A model rates its own outputs higher than equally good outputs from a different model. Mitigation: use a stronger (or at least different) model in the judge slot.
Two techniques that hedge against single-judge variance: samples multiple verdicts from the same judge and keeps the consensus, and across a small panel of different-model judges is a stronger version of that when you can afford it.
Whatever you do, hold out a small set of human-judged examples as a calibration set. Run the LLM judge on it. The gap between the LLM's verdicts and the humans' verdicts is your bias budget, and it tells you which results to trust and which to double-check. The same trust-but-verify logic applies to any model output you plan to act on.
Key takeaways
- Judges are not neutral. A strong LLM grading weaker outputs still shows position bias, length bias, and self-preference bias. Measure each one before you trust a score.
- Pairwise comparison is usually more reliable than rubric scoring. But it only holds up if you randomize order and run both directions.
- Best-of-N evaluation turns a judge into a cheap quality filter. Quality scales sub-linearly in N and degrades when the judge is weaker than the generator.
- When the generator and the judge are the same model, you are grading the model's handwriting with its own ruler. Prefer a different (or stronger) model in the judge slot, and hold out a human-judged sample to bound the bias budget.