Posts
Guides, essays, and deep dives.
-
 machine-learning
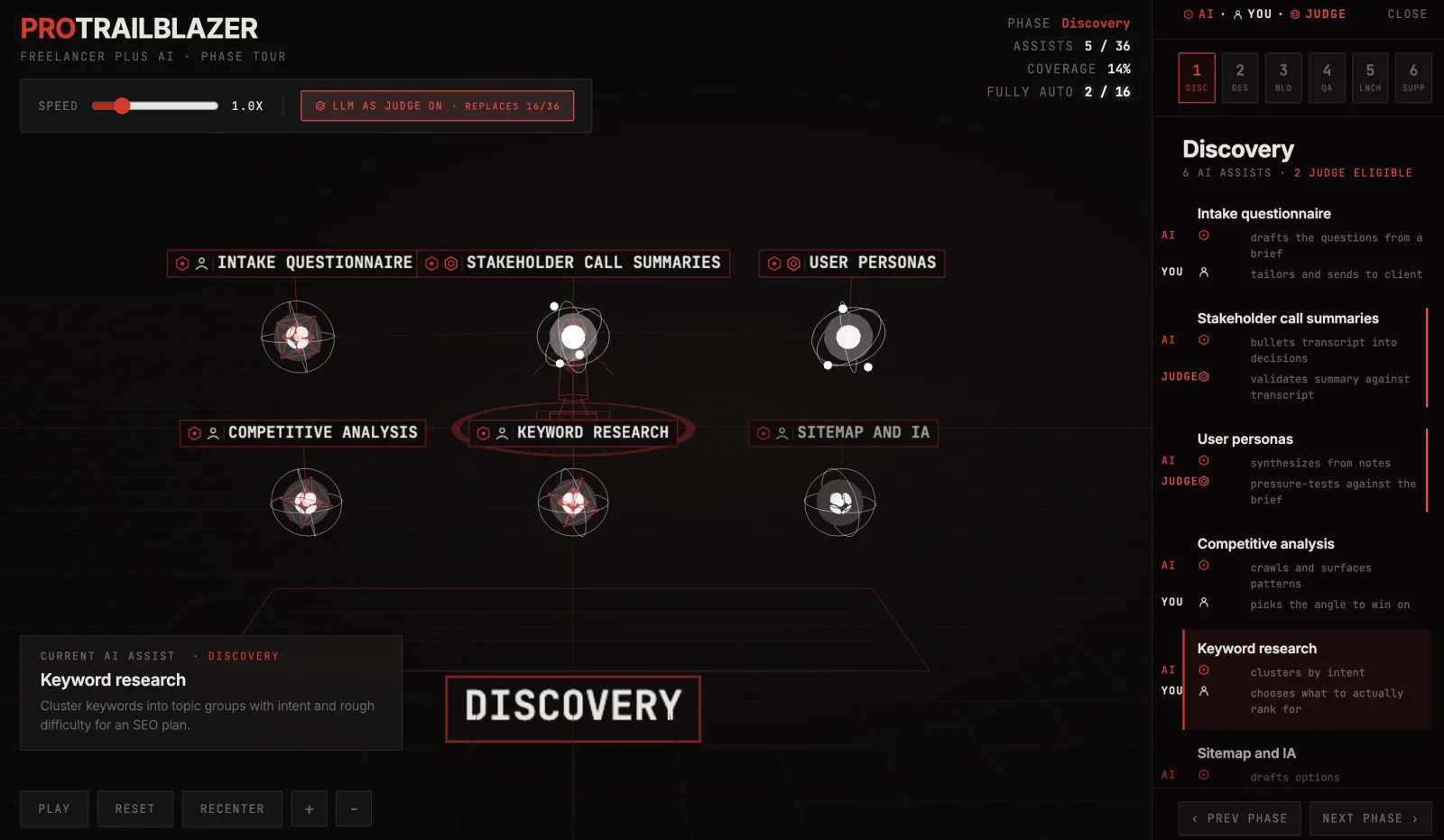
machine-learning36 ways AI works alongside a freelance web developer
A 3D tour of six freelance web project phases with six AI assists each, plus a toggle showing which 16 of 36 handoffs can drop the human approver.
-
 machine-learning
machine-learningAgentic workflows: how AI agents chain business tasks
A radial simulation of an agentic AI workflow, plus a plain-language look at what agents do, why the orchestrator matters, and what breaks first for SMBs.
-
 machine-learning
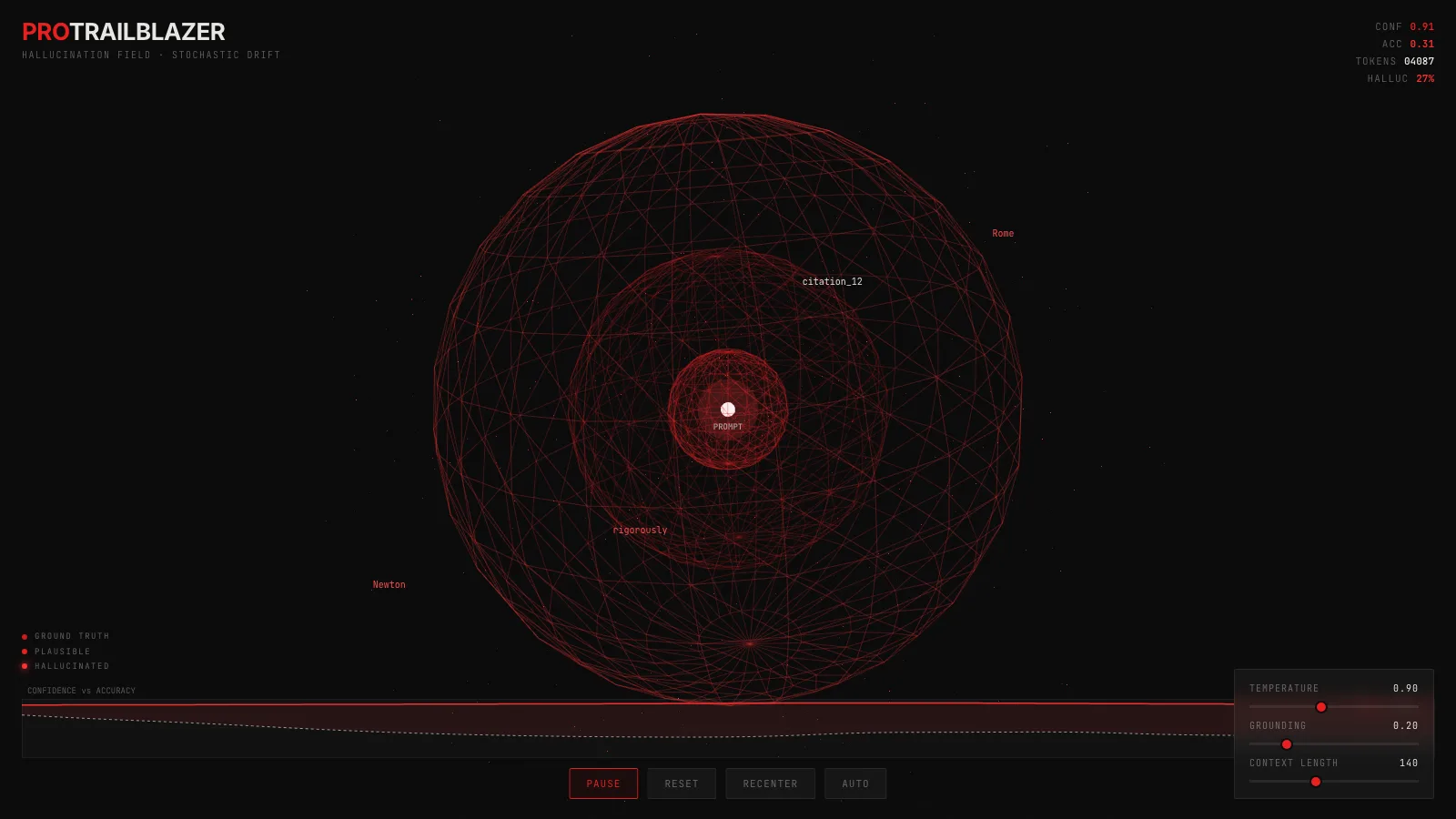
machine-learningLLM hallucination: why confident answers drift from truth
A 3D demo of language-model sampling: tokens drift outward as text moves from grounded to fabricated, while the model's confidence barely moves.
-
 developer-tools
developer-toolsModel Context Protocol: how AI apps plug into tools and data
Watch JSON-RPC messages flow between an MCP host and its servers as the client discovers tools, invokes them, and streams results back to the model.
-
 machine-learning
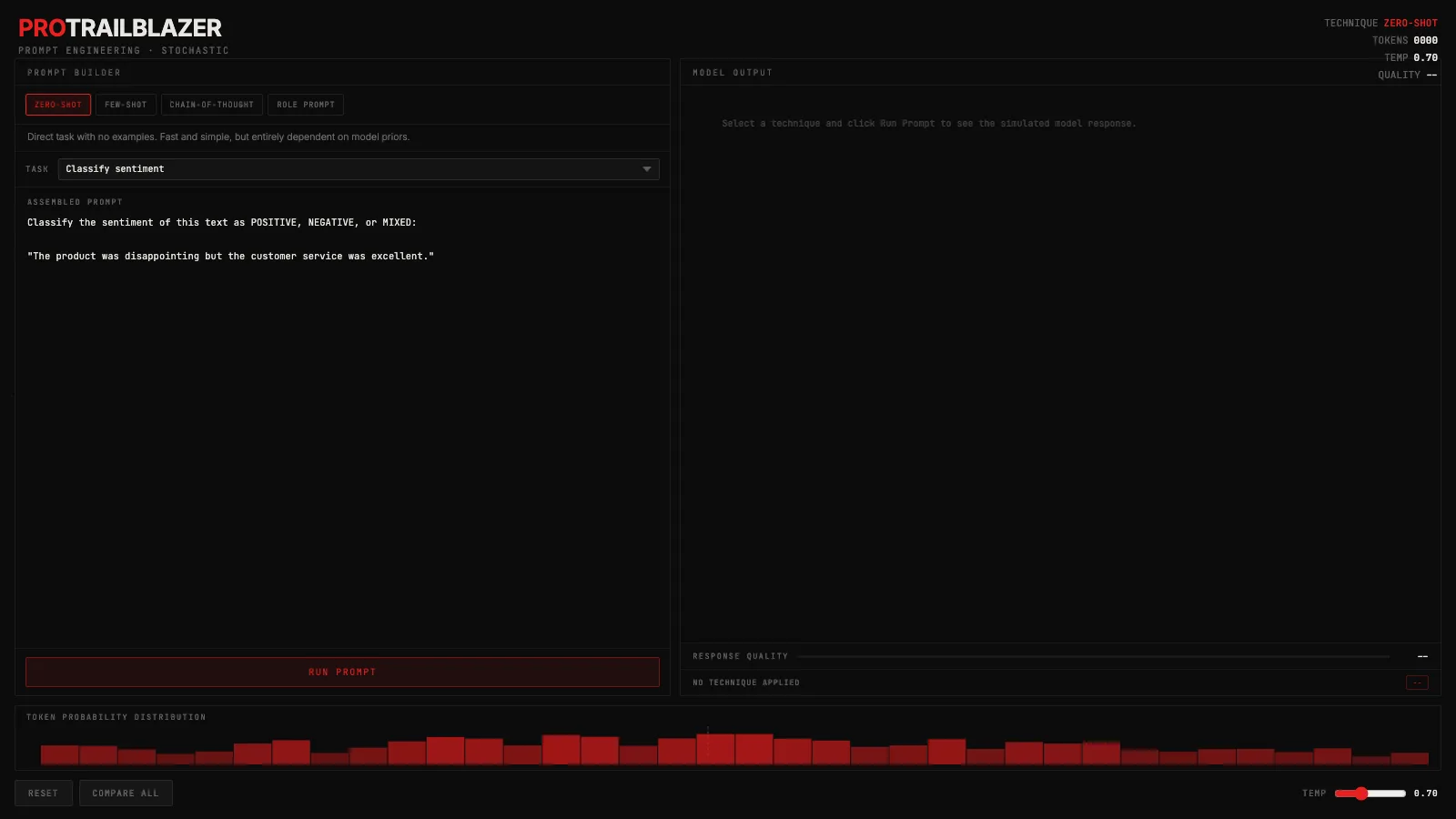
machine-learningPrompt engineering: how technique shapes what models say
Zero-shot, few-shot, chain-of-thought, and role prompting explained with an interactive demo. See how technique shifts token probability and output quality.
-
 machine-learning
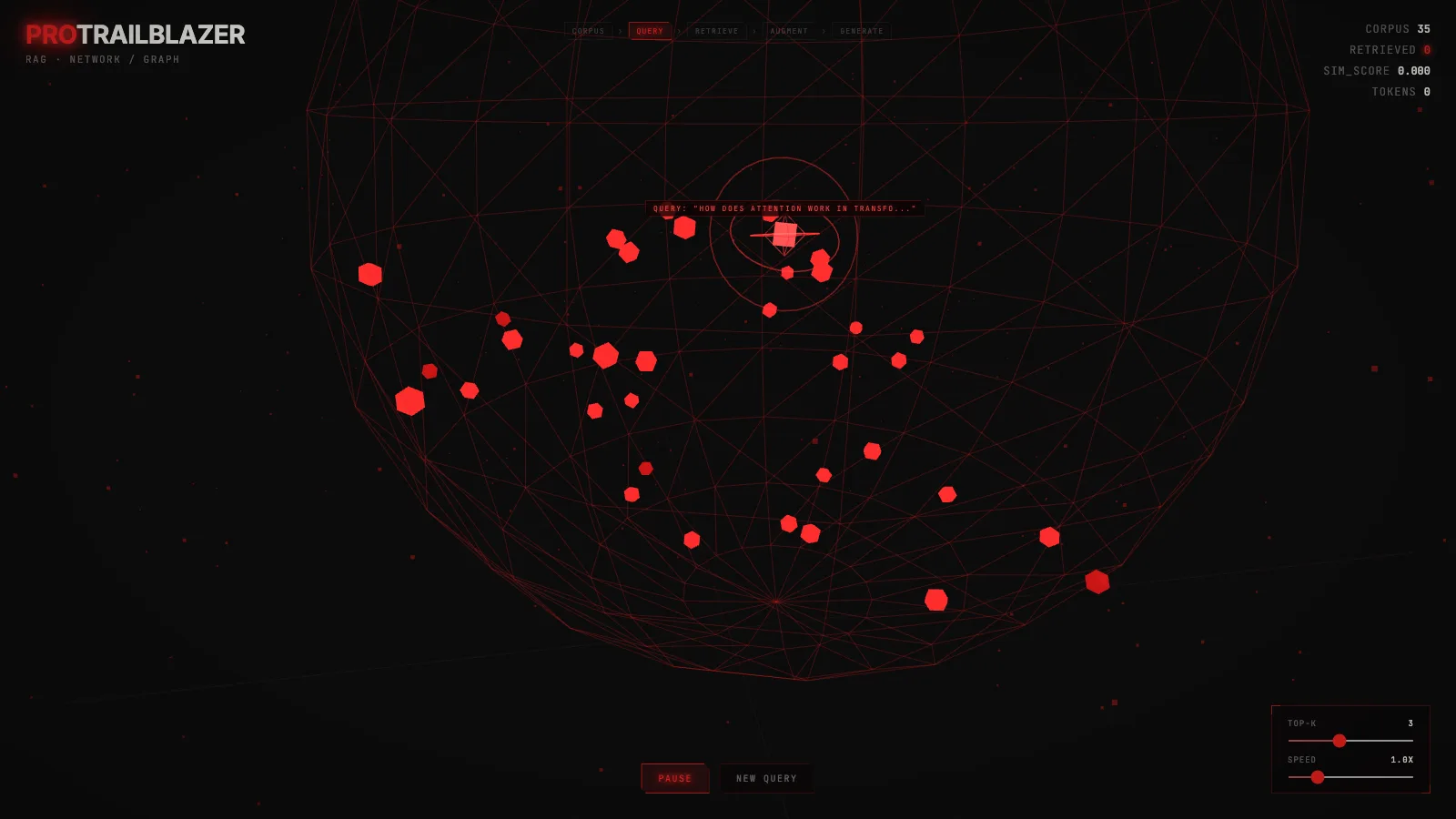
machine-learningRetrieval-augmented generation: how LLMs look things up
A 3D demo of a RAG pipeline: a query vector searches a corpus, the top-K nearest chunks light up, and the LLM grounds its answer in the retrieved text.
-
 machine-learning
machine-learningAutoregressive generation: how an LLM writes one token at a time
A plain-English look at how LLMs actually produce text, with a 3D demo of the KV cache that makes inference feasible and what would happen without it.
-
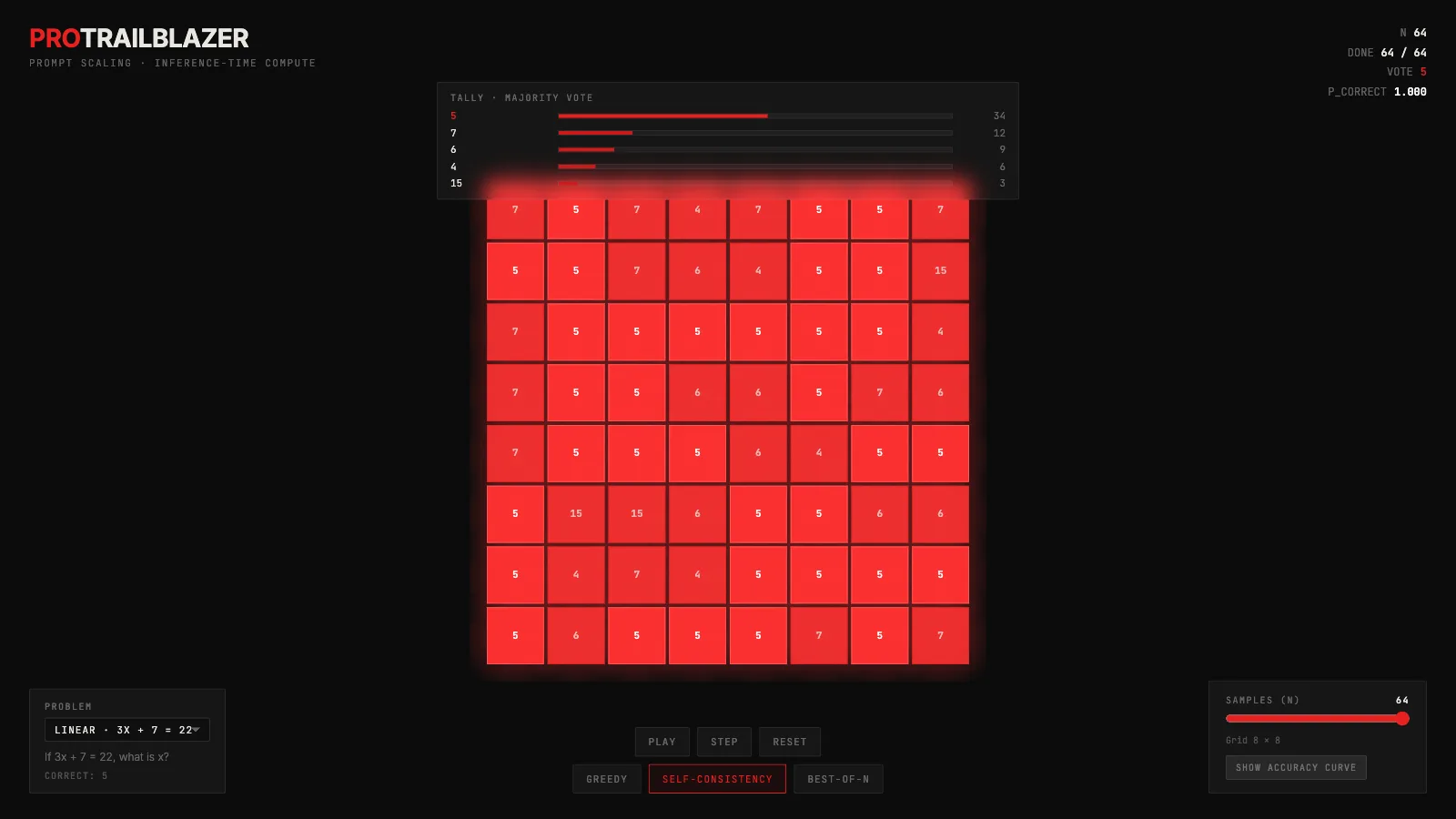 machine-learning
machine-learningInference-time compute: more samples, smarter answers
A plain-English look at inference-time compute, with a live grid of reasoning chains that vote on the same question and surface the real accuracy-vs-N curve.
-
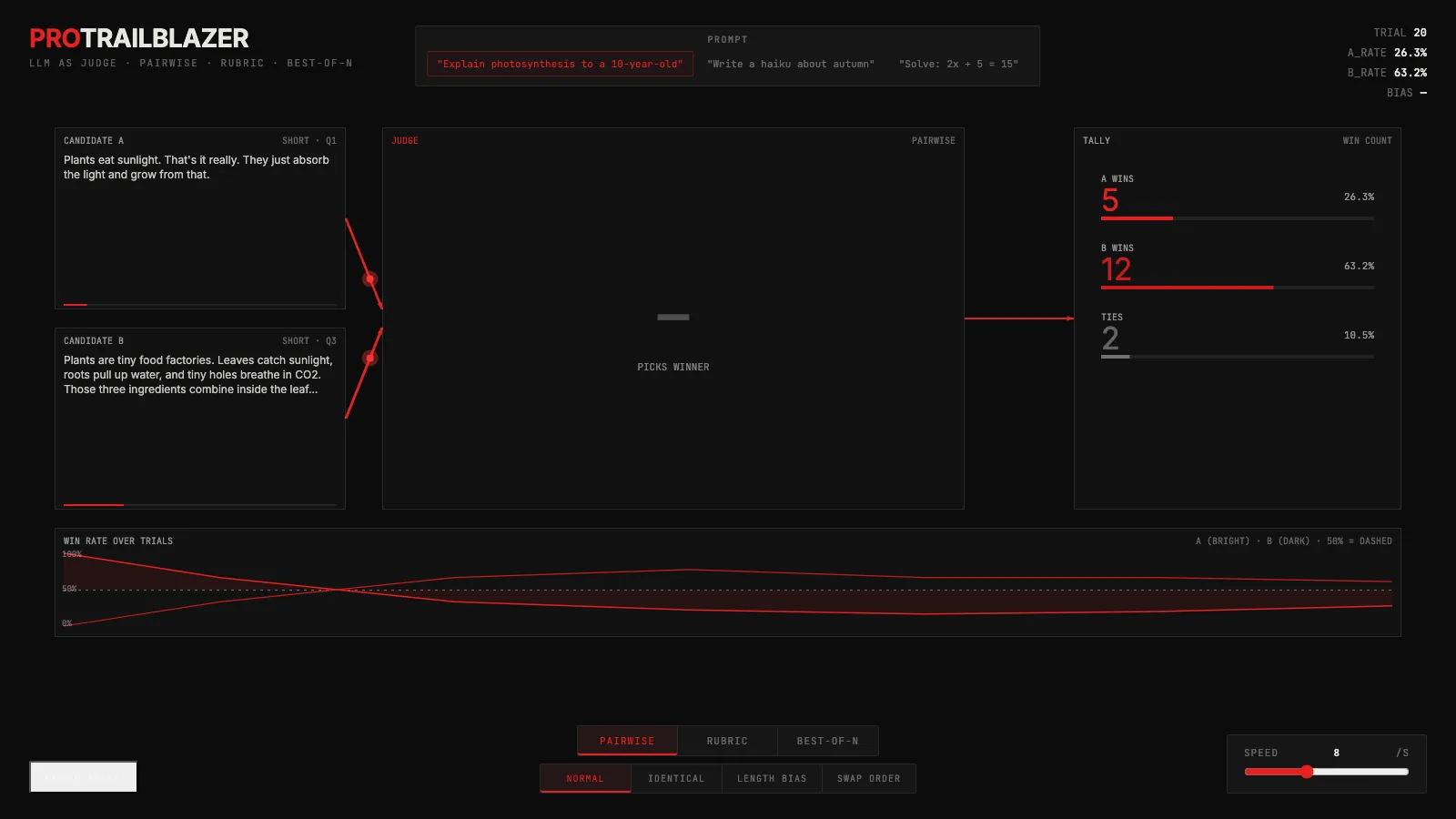 machine-learning
machine-learningLLM as judge: one model grading another
One LLM grades another: a live demo of pairwise, rubric, and best-of-N judging, plus the position, length, and self-preference biases you have to probe for.
-
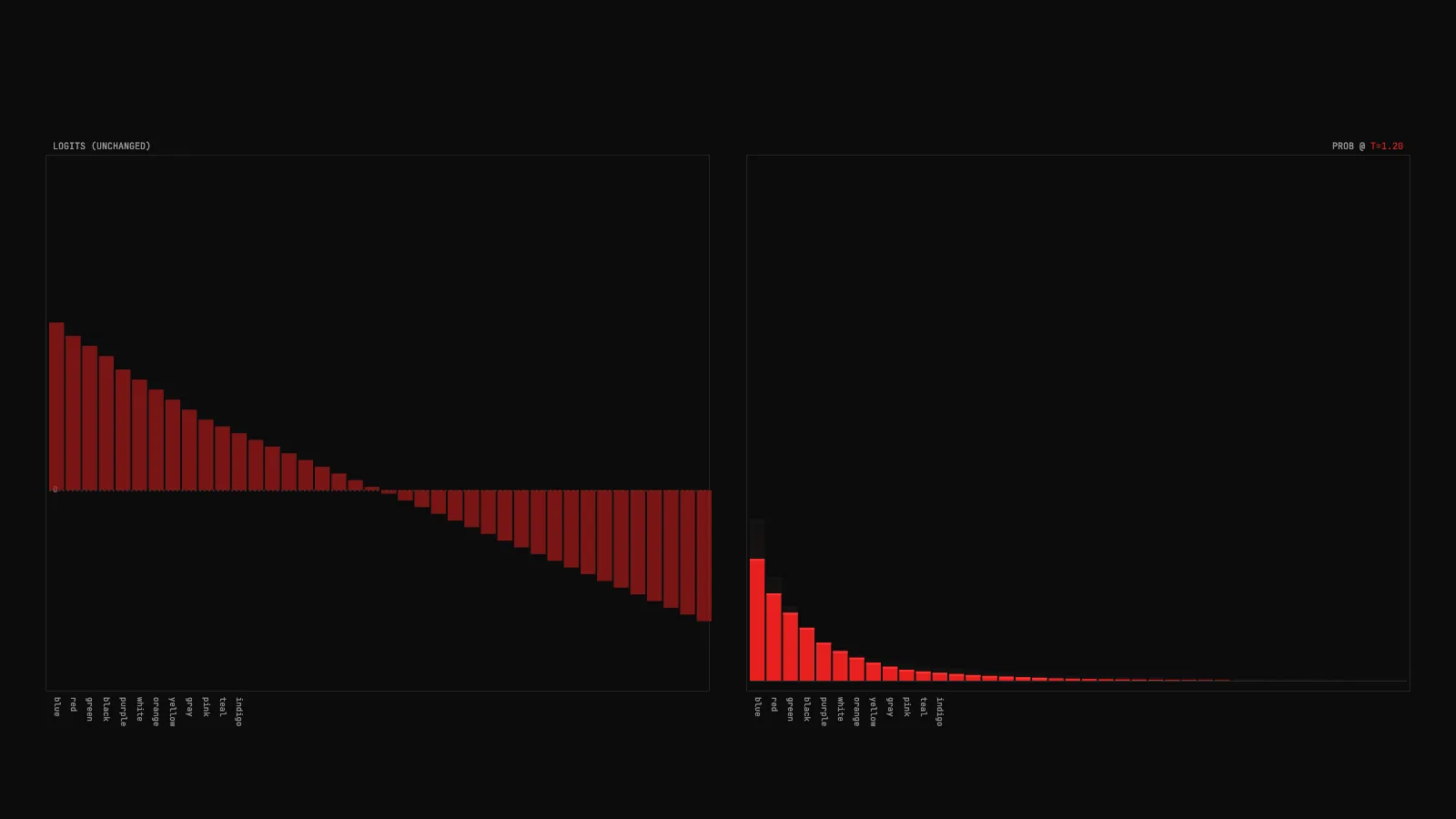 machine-learning
machine-learningLLM temperature: one number that reshapes the next-token distribution
A plain-English look at temperature in language model inference, with a live demo that shows exactly what the parameter does to the probability distribution.
-
 machine-learning
machine-learningMixture of Experts: sparse routing for huge models at fast-model cost
A plain-English explainer on MoE models with a live 3D demo showing how tokens route through a small subset of experts at each layer.
-
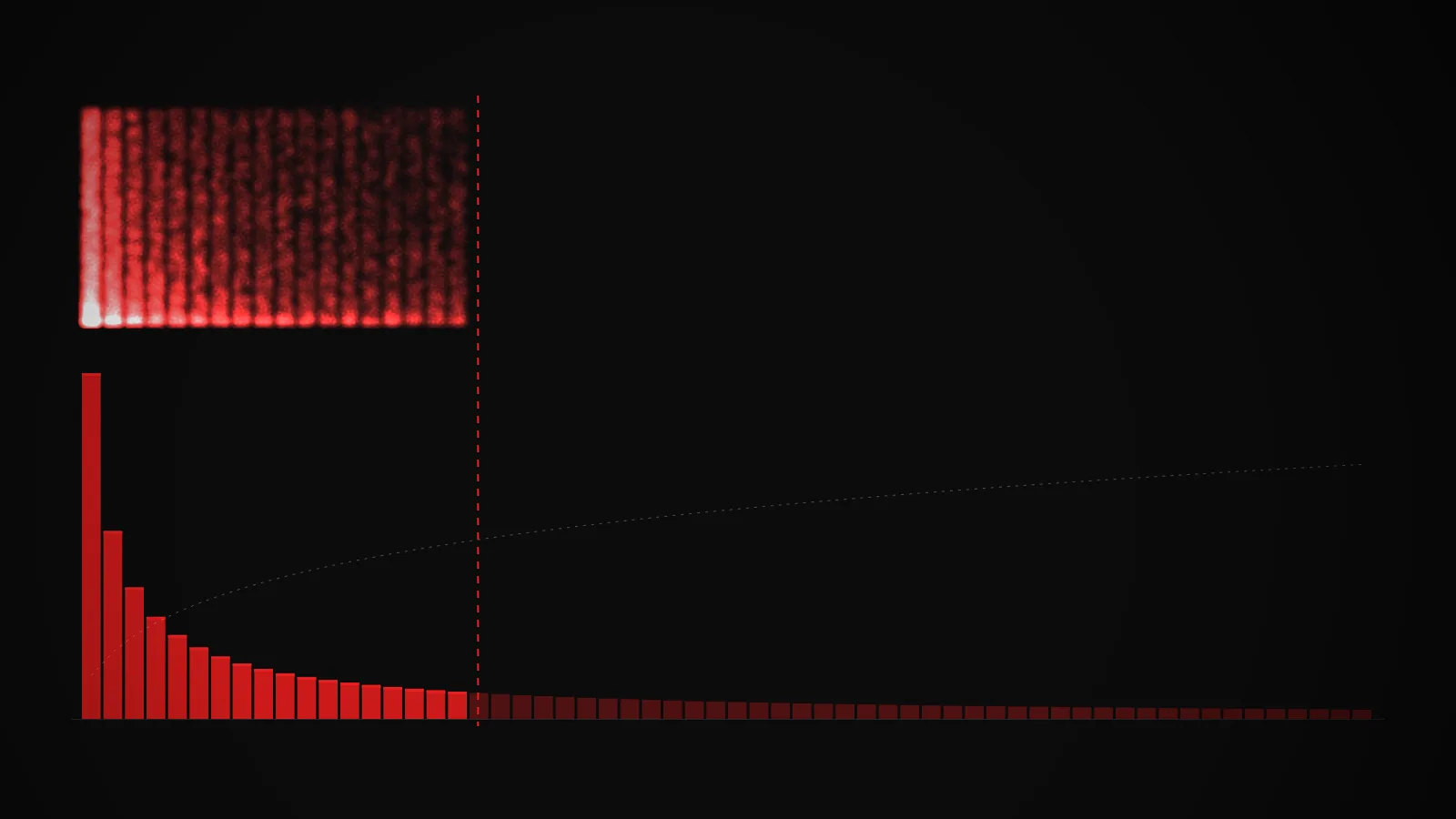 machine-learning
machine-learningTop-k and top-p sampling: how an LLM picks its next token
A plain-English look at the two cutoff strategies that decide which tokens a language model is allowed to sample from, with a live interactive demo.
-
 machine-learning
machine-learningEmbeddings in 3D: how models turn words into coordinates
Type a sentence, watch each token land as a point in 3D space. Click any token to inspect its vector and see which other tokens it's nearest to.
-
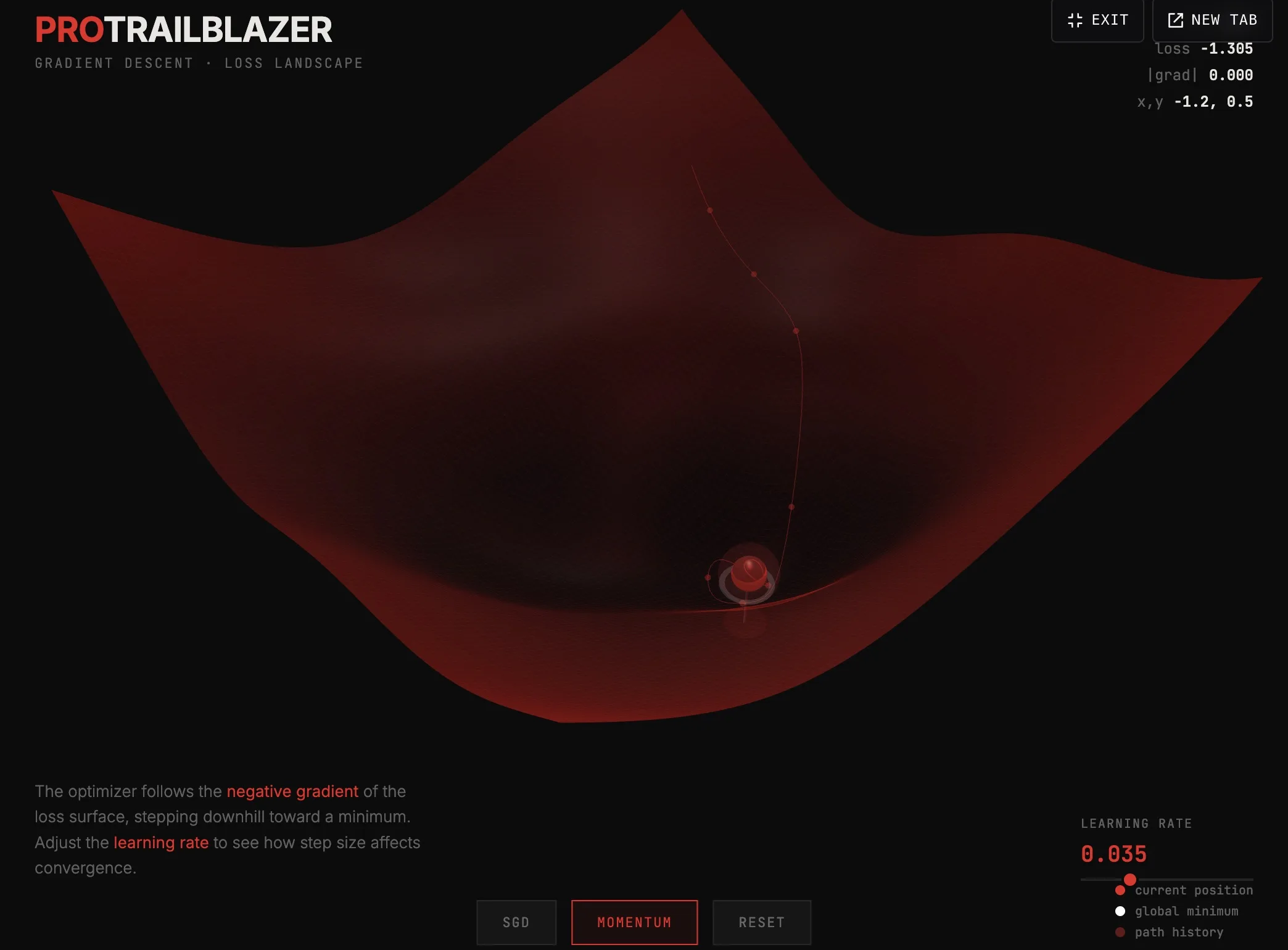 machine-learning
machine-learningGradient descent: how a model rolls downhill
Watch a simulated model find a low spot on a 3D loss surface. A plain-English look at the optimizer that drives modern machine learning.