Gradient descent: how a model rolls downhill
Last updated: April 18, 2026
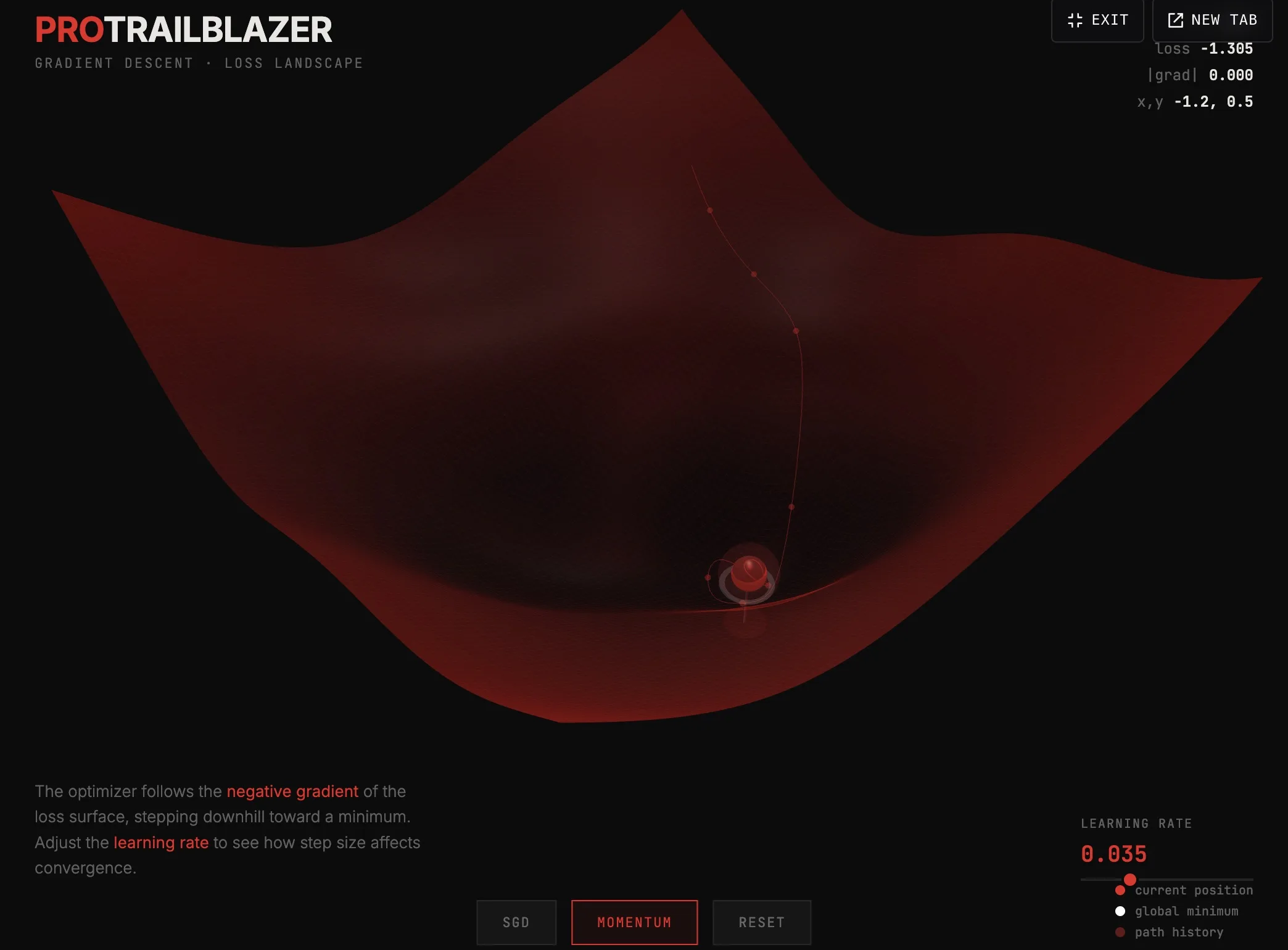
The interactive below shows the algorithm in action. Drag to spin the camera, adjust the learning rate, switch between SGD and momentum, and watch the red ball find a minimum. Click the fullscreen button in the top-right of the demo for a closer look.
Demo
Gradient descent on a loss landscape
Watch a simulated model roll downhill across a 3D loss surface to find a low spot. Switch between SGD and momentum, drag the learning rate, spin the camera.
What you're seeing
The surface is a loss landscape. Each point on it represents a possible setting for the model's weights. The height at that point is how wrong the model would be with those weights. The red ball is the current state. reads which direction is downhill (the negative gradient) and steps the ball that way.
A few things to try in the demo:
- Move the learning rate slider. Too small and the ball barely moves. Too large and it overshoots, bouncing around instead of settling.
- Switch from SGD to momentum. SGD takes one step at a time. Momentum keeps a fraction of the previous step's velocity, so the ball can roll through small bumps instead of getting stuck on them.
- Reset and restart. The ball starts in a randomized position. Sometimes it finds the global minimum (the white marker). Sometimes it settles into a local one. That is the entire game.
How it actually works
Real models have millions of weights, not two. The loss landscape is millions of dimensions, not three. But the math is identical: at each step, the optimizer computes the gradient of the with respect to every weight, then nudges every weight a small amount in the direction that lowers loss. That nudge is the learning rate times the negative gradient.
Two things make this hard in practice:
- Local minima. The landscape is bumpy. The ball might find a low spot that isn't the lowest. In high-dimensional spaces this matters less than it sounds (most "minima" turn out to be saddle points), but it remains a real concern.
- Vanishing or exploding gradients. In deep networks the gradient signal can shrink toward zero or blow up by the time it reaches the early layers, depending on the architecture and activation choices.
is the algorithm that calculates the gradients efficiently across every weight in the network. The repeats this forward-pass-then-backward-pass cycle billions of times.
Key takeaways
- Gradient descent steps weights downhill on a loss landscape.
- The learning rate controls step size. Too small wastes time. Too large misses the bottom.
- Momentum carries velocity from the previous step, helping the ball escape small local minima.
- The same idea scales from this 3D toy to the millions-of-dimensions reality of a production model.