LLM hallucination: why confident answers drift from truth
Last updated: April 24, 2026
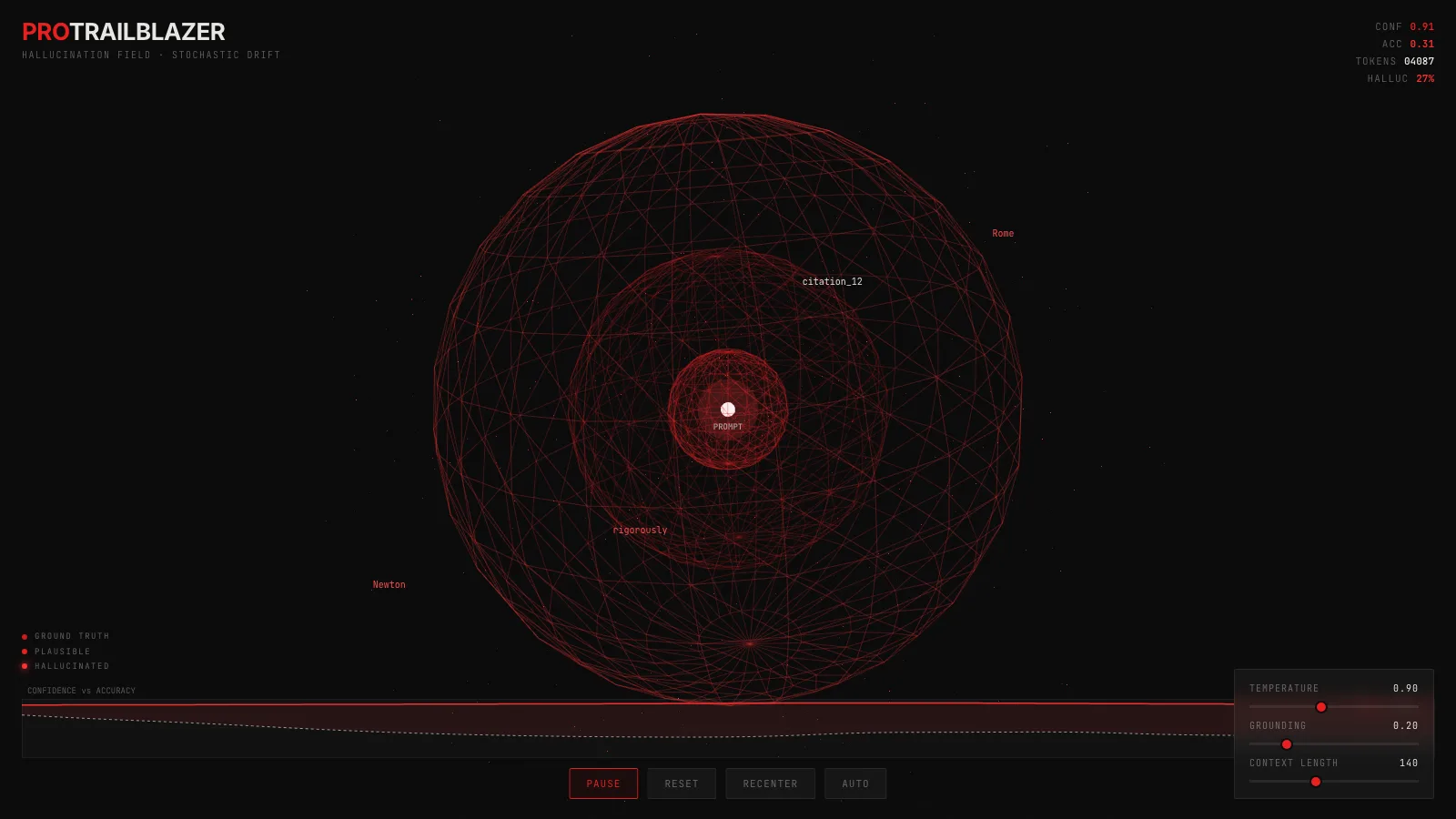
The interactive below shows a language model's sampling process as a 3D particle cloud. Drag to orbit through it, pinch or scroll to zoom, and watch how the field shifts when you change the temperature or the grounding slider. Every red particle is a token the model could sample next. The further it drifts from the white anchor, the further the generated text has wandered from the truth.
Demo
LLM hallucination in 3D sampling space
Orbit through a 3D particle cloud of sampled tokens. Radial distance is drift from ground truth, brightness is the model's reported confidence, and the gap between the two is what hallucination actually looks like.
What you're seeing
The white point at the center is the prompt. It is the one thing the model knows for sure. Everything else in the field is guessed.
Each red particle is a candidate the model could pick next. Radial distance from the anchor is how far that token has drifted from the ground truth. Brightness is the model's reported confidence in its pick.
Three faint wireframe shells carve that space into zones:
- Truth. Inside here, the token is close to what a grounded answer would say.
- Plausible. Past this shell the token is still coherent but no longer directly supported.
- Hallucination. Past this shell the model is inventing. Particles here are a little larger and a little brighter because the model did not lose confidence when it crossed the line.
A few things to try in the demo:
- Push the temperature up. The cloud inflates. More tokens cross the hallucination shell, and the HALLUC readout in the top-right climbs.
- Pull the grounding slider toward one. A soft force drags the cloud back toward the anchor. This is the effect of retrieval, citations, or a tight system prompt. Accuracy goes up. Confidence barely moves.
- Watch the strip chart. It plots running confidence (solid red) against accuracy (dashed). The shaded band between them IS the hallucination zone. When it opens, the model is confidently wrong.
- Orbit around the cloud. The drift is spherical, not a 2D disc. Some directions get denser than others as the random walk finds local channels, the same way certain phrasings tend to pull a model into certain fabrications.
How it actually works
A language model picks each next token by turning its internal state into a set of , passing those through a to get a probability distribution over every token in its vocabulary, and sampling one. The distribution reflects how well each token fits the current context. It does not know whether any of those tokens are factually correct. Plausible and correct are different constraints, and the model only optimizes the first one.
scales the logits before softmax. Low temperature makes the distribution spiky and concentrates the sampler on the top candidate. is the limit case, temperature zero, which always picks the top token. High temperature flattens the distribution and widens the range of likely picks, which is what inflates the cloud in the demo. Neither setting changes whether the top candidate is actually true, so hallucinations happen across the whole range.
Other sampling constraints like cap how far into the tail the sampler can reach. They reduce the chance of a wildly off-track token on any single step, but they do nothing about a confidently wrong token that is still inside the nucleus.
The reason drift shows up as a gradient in the demo and not a single jump is that each sampled token is appended to the context the next step conditions on. One wrong pick shifts the distribution the model sees at the following step, which shifts the one after that. By the time a generation is fifty tokens long, a small early drift has re-anchored the rest of the answer around a fabrication, and every subsequent token is confidently consistent with the wrong premise.
What fights hallucination in practice
Production systems fight this in four places. Retrieval injects authoritative text into the before generation, so the grounded tokens are already in the conditional distribution. Tool use forces the model to look a fact up rather than sample one. samples multiple answers and votes, which smooths out single-path drifts. Post-hoc verification checks the output after the fact. Each of these is a version of the grounding slider in the demo: shrink the space the sampler is allowed to walk through.
The same controls can also be tuned at the sampler itself. See our walkthroughs on temperature and on top-k and top-p sampling for a closer look at the specific knobs this post introduces.
Key takeaways
- Confidence and accuracy are different signals. A model's internal probability for a token measures how well the token fits the local language pattern, not whether it is factually true.
- Temperature does not cause hallucination, it spreads it out. At temperature zero the model still hallucinates, it just commits to one confident wrong answer instead of sampling many variants.
- Grounding (retrieval, tool use, citations) shrinks the hallucination zone by pulling the distribution back toward verified tokens, but it does not remove the mechanism that produces drift in the first place.
- Drift compounds across tokens. Each sampled token joins the context that conditions the next one, so a single fabrication early in a sequence can re-anchor the rest of the answer around it.