Retrieval-augmented generation: how LLMs look things up
Last updated: April 24, 2026
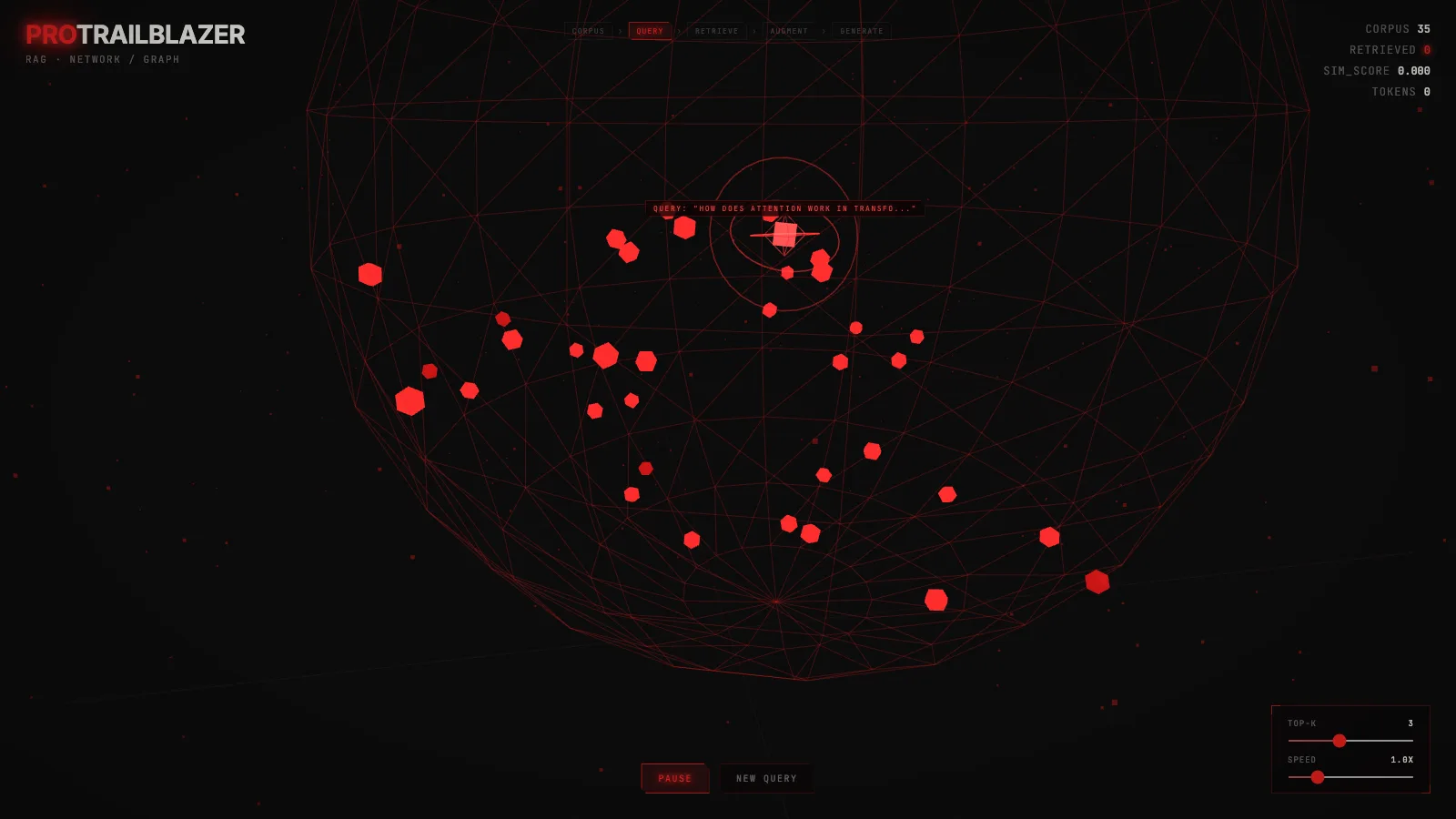
The interactive below shows a RAG pipeline in 3D. A query fires into a cloud of document chunks, the closest ones light up, and those chunks are what the LLM sees when it writes its answer. Drag to orbit, scroll or pinch to zoom, and hit 'new query' to send another shot into the corpus.
Demo
Retrieval-augmented generation in a 3D document corpus
Orbit through a 3D corpus of document chunks. A query vector fires in, its top-K nearest neighbors light up, and the retrieved chunks get handed to the LLM to ground its answer.
What you're seeing
Each dim red point is a chunk of a document that has already been turned into a vector. A chunk is a paragraph or a section, not a whole document, because retrieval works better when each unit is small enough to be about one thing.
When you fire a query, a brighter node appears at the query's location in the same vector space. Lines draw from the query to its top-K nearest neighbors, and those neighbors are what gets handed to the LLM as context. SIM_SCORE is the cosine similarity of the best retrieved chunk. TOKENS is the size of the packet being sent to the generator.
A few things to try in the demo:
- Drop top-K to 1. The model gets exactly one chunk. If that chunk is right, great. If it is almost-right, the model has nothing to cross-reference and will fall back on its parametric memory, which is where hallucinations come from.
- Raise top-K to 6. More context, more chances of including the right chunk, and more chances of drowning it in irrelevant ones. Watch how quickly the token count climbs.
- Orbit the cloud. Clusters are meaningful. Nearby chunks are semantically similar because they share a region of embedding space. Queries land in whichever cluster best matches their meaning.
How it actually works
RAG has four steps: index, embed, retrieve, generate.
Index. Documents are split into chunks, typically 300 to 800 each. Boundaries matter: splitting mid-sentence or mid-idea destroys retrieval quality. Structure-aware splitting uses headings, paragraphs, or sentence boundaries.
Embed. Each chunk is passed through an embedding model that maps it to a high-dimensional vector. Similar text lands in similar regions. Our post on goes into what those vectors actually encode.
Retrieve. At query time, the query itself is embedded with the same model and the system finds the K chunks closest to the query vector. Cosine similarity is the usual distance. Production systems use approximate nearest-neighbor indexes (HNSW, IVF, ScaNN) because brute-force scoring is linear in the corpus size.
Generate. The retrieved chunks are formatted into the alongside the question, and the LLM generates its answer conditioned on them. The prompt usually asks the model to cite which chunk it used for which claim. Because the model sees the source text at inference time instead of only relying on what it memorized during training, fresh information can be served without retraining. That is the whole value proposition of RAG.
Where RAG struggles
RAG is a retrieval problem wearing a generation hat. Most failures are retrieval failures in disguise:
- The answer requires synthesis across many chunks. Top-K pulls chunks independently. If the real answer needs paragraphs from fifteen chunks scattered across the corpus, top-K equal to five will miss most of them.
- The query is vague. A question like 'what do we know about X' will pull chunks that match the phrase, not chunks that contain the actual information. Query rewriting and hybrid lexical-plus-vector search help.
- The retrieved chunk is almost-right. The model reads an adjacent paragraph to the one that would have answered, and extrapolates. This is the same hallucination failure mode, still inside the confident zone, but now with citations pointing at the wrong source.
Upgrades most teams reach for first: chunk-boundary-aware splitting, re-ranking the top-K with a cross-encoder, hybrid search (vector plus BM25), and query expansion. Reach for those before you start tuning the generator.
Key takeaways
- RAG is a retrieval problem wearing a generation hat. If retrieval surfaces the wrong chunks, the model's answer will be confidently wrong about the wrong documents. Tune retrieval before you tune prompts.
- Top-K is the most important lever. Too low and you miss the chunk that would have answered. Too high and the model drowns in irrelevant text and hallucinates anyway. Most production systems land between 3 and 6.
- Chunk boundaries matter more than chunk content. Fixed-size slicing can hide the one sentence that would have answered. Use structure-aware splitting.
- RAG shrinks the hallucination zone, it does not close it. Pair RAG with citation rendering so readers can check what the model actually read.